自然言語処理の機械学習によるSTS 類似度計算編(4)
前回までつらつら稚拙で怪しいNLPに関する文章を書いてきたが、要は最終的には結果が一番重要である。
今回のSTSタスクで行いたい、または、確かめたいことをまとめると以下である。
2つの文の意味の類似度を計算できるか語 ...
自然言語処理の機械学習によるSTS FineTuning編(3)
前回からに引き続きゆるーく自然言語処理について書く。
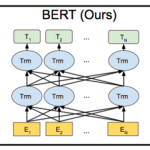
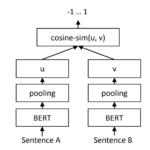
文の特徴量抽出前回までにElectraで事前学習(pretraining)を行い、高い精度のwordの特徴量を取得するまでできた。しかし、STSでは2つの文の意味類似性 ...
自然言語処理の機械学習によるSTS Electra事前学習編(2)
前回に書いた通り、文の意味をコンピュータが理解するというのは難しいことである。
自然言語処理の機械学習によるSemantic Textual Similarity (STS)(1)
そして機械学習、とりわけBE ...
自然言語処理の機械学習によるSemantic Textual Similarity (STS)(1)
ゆるーく自然言語処理(NLP)について書く。
コンピュータには文の意味が理解できない?多くのAIなんちゃら関係の書籍やそれを要約紹介するYoutubeを見たことはあるだろうか?その中でもNLPに関連する有名なセリフがありま ...
subword-nmtで語彙を作成

自然言語関連の処理の際、文字を形態素解析で分解し機械学習など実施すると思う。有名な形態素解析ツールはMecabやjumanかと思うが、膨大なテキストデータを形態素解析で分解し、ユニークな単語一覧を作成すると膨大な単語数のvocabがで ...