自然言語処理の機械学習によるSTS Electra事前学習編(2)
前回に書いた通り、文の意味をコンピュータが理解するというのは難しいことである。
そして機械学習、とりわけBERT系が高いベンチマークを記録しているので、これに挑戦した。
Electra事前学習(pre-training)
Modelは『Electra』を使用。ElectraはBertと同じ構造のモデルだが、事前学習の方法が異なる。
https://github.com/google-research/electra
そして、今回新たに一から事前学習を実行することにした。以下の条件で行った。
- モデルサイズはBaseとLarge
- 約3億5000万の日本語テキスト文データ(Textデータサイズ85GB)
- Base(batch size: 256、step: 1.9M)、Large(batch size: 1024、 step: 1.4M)
- Vocabサイズ: 39168
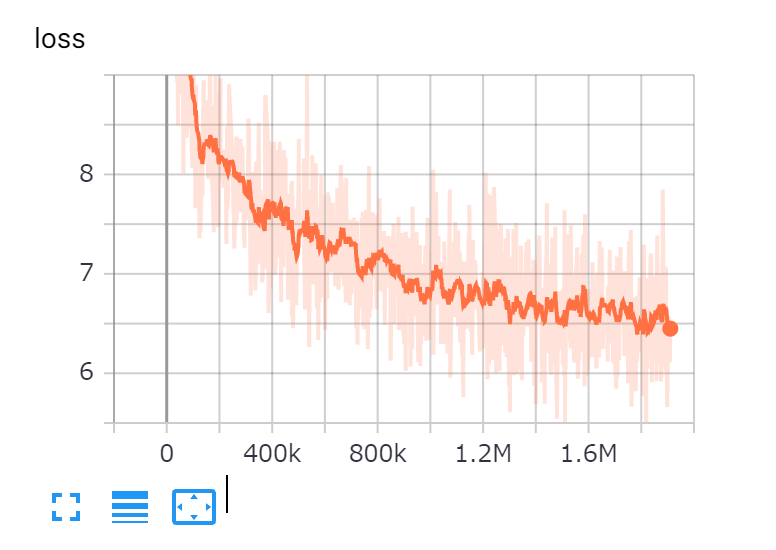
【Base】
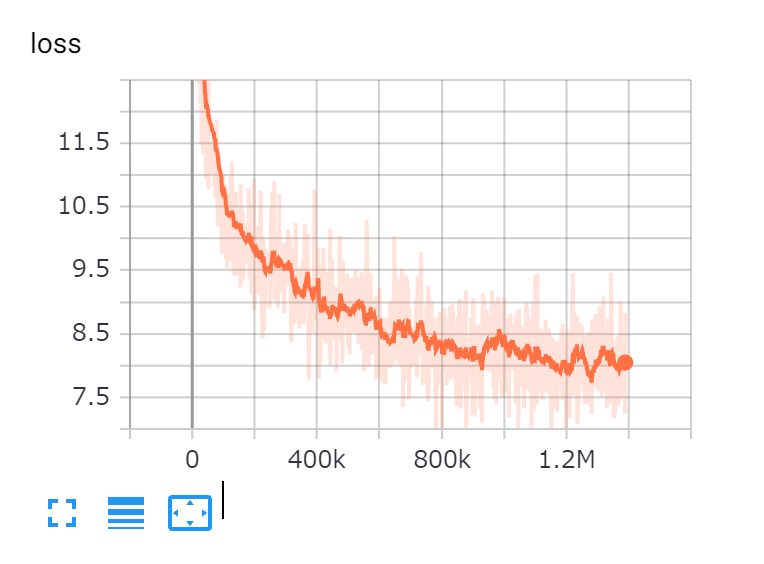
【Large】
特にLargeはTPU(32core)でぶん回して1か月半かかった。Googleの研究より多めのstepを採用しているのは、lossがまだまだ下がりそうだったからである。また、Baseサイズのモデルは実は次のような組み合わせで複数用意した。
- SentencePieceによるVocab作成データ使用
- Mecab-neologd&BPEによるVocab作成データ使用
そして今回達成したいタスクの検証データでのPearson Correlationは、1.モデルは平均0.81程度、2.モデルは平均0.83程度。どちらも精度が低いように見えるが、これは今回のプロジェクトで処理すべきデータ(少し複雑な文章データ)の類似データでevalした結果なので、このくらいの数値になっている。(詳細は割愛)
とにかくなぜか理由は断定できないが、用意したデータセットではBPEの方が意味類似タスクについては高いスコアがでるようだ。世間的にはSentencePieceの方が良いような風潮があるようだが、高いスコアの方を採用しない理由が見当たらなかったので、BPEによりvocabを作成することにした。
この事象に関する勝手な推測だが、Mecab-neologdでの形態素解析では、特定の意味を持つ品詞への分解を伴うので、それぞれのトークンの持つ"意味"が明確になりやすいのかもしれない。正直詳しくはわからない。
Electraによる特徴量
これである文の特徴量を計算してみる。対象の文は次のものでLargeサイズのモデルでやってみる。
「私は人間です。」
tensor([[[-0.2846, -0.7042, -0.3056, ..., -0.4577, 0.4530, 1.8807],
[-0.3866, -0.5897, -0.3665, ..., -0.5530, 0.4648, 2.0057],
[-0.2908, -0.1992, -0.7022, ..., -0.6455, 0.1784, 1.4405],
...,
[-0.1906, -0.7403, -0.1799, ..., -0.4659, 0.4365, 1.9108],
[-0.1465, -0.5993, -0.2985, ..., -0.3114, 0.5353, 1.7178],
[-0.1158, -0.6635, -0.0404, ..., -0.3841, 0.2492, 1.8801]]],
grad_fn=<NativeLayerNormBackward>)
また、tensorのsizeを見てみると次のようになる。
torch.Size([1, 8, 1024])
Largeサイズの出力は1024次元で、2つ目の「8」はtokenの数であり、['[CLS]’, '私’, 'は’, '人間’, 'で’, 'ある’, '。’, '[SEP]’]の8つである。
一つずつのトークンの特徴量が出ていることがわかる。
試しに以下の2つの文章の同じ単語「人間」の特徴量のコサイン類似度を計算してみた。
「私は人間です。」
「私は妖怪人間ベムだ。」
「人間」のcos sim = 0.804
同じ単語(token)でも異なる特徴量が出力されることがわかる。これはBERTが前後の文を考慮して単語のfeatureを計算していることを表す。しかしGoogleのペーパーではこの事前学習での特徴量のみではNLPタスクをこなすうえで役に立たないと書かれている。つまり上記でいうと、この8つの1024次元を平均して使用したり、先頭の[CLS]の値を使用することで文全体の特徴量とすることは間違いであるということだ。
いずれにせよ、BERT系では文脈を意識して単語の特徴量を算出することができるということだ。