自然言語処理の機械学習によるSTS FineTuning編(3)
前回からに引き続きゆるーく自然言語処理について書く。
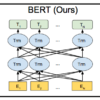
文の特徴量抽出
前回までにElectraで事前学習(pretraining)を行い、高い精度のwordの特徴量を取得するまでできた。しかし、STSでは2つの文の意味類似性を計算するが、Bertで出力される特徴量の集合は文を構成するトークンの数に依存するため、可変となる。そのためこのままでは2つの文のコサイン類似度を計算することはできない。例えば以下の2つの文の特徴量をLargeモデルで出力した場合以下のシェイプとなる。
私は人間です。
torch.Size([8, 1024])
私は妖怪人間ベムです。
torch.Size([10, 1024])
このように、文の長さ(tokenの数)によってベクトルの構造が異なり、文の特徴量としては使うことはできない。そこで1つの文を[1024]のサイズの固定長のベクトルにして使用することにするわけだ。
簡単に思いつくのは、それぞれのベクトル値の平均を計算して固定長にするや、先頭のトークンである[CLS]の特徴量を使用するというだ。しかし研究ペーパーでは、これらはひどい精度で使い物にならないと報告されている。
そこで、BERTのword embeddingsをPooling層でプーリングするネットワークを構築して、それをファインチューニングすることが良いと説明されている。poolingによって固定長となったベクトルをコサイン類似度で計算することで文の意味を比較できるというわけだ。
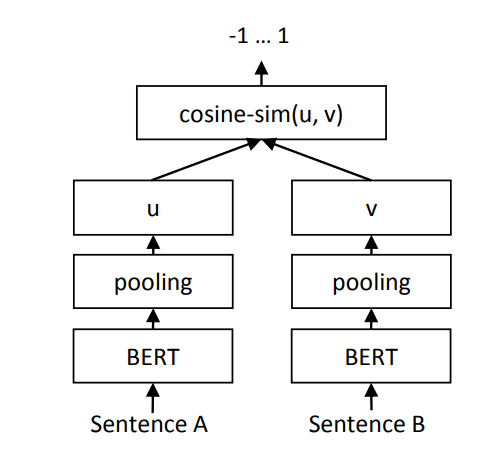
STSファインチューニング
詳細は割愛するが、NLIデータセットやSTSのデータセットを用意して、上記のSTSネットワークをファインチューニングする。ここで用意するSTSの学習データはクオリティの高いセットが膨大に必要である。正直このクオリティの高いデータを用意するのが一番大変であり、膨大なコストと時間がかかる。
はじめは適当にテキストデータをスクレイピングなどで取得して、TFIDFを使用したり、ニュースサイトの同一記事の類似性などを考慮してたくさんデータを作成できると考えた。しかしこれらのデータは質が低く、最終的なモデルは求める水準にははるかに及ばなかった。
考えてみれば当然で、人間でもしっかり読まなければ類似性を認識するのが難しいくらいのものを機械的に判断してデータを用意できるなら、そもそもこのSTS機械学習モデル自体いらないわけだ。それに文の中に使われている単語・品詞の意味の類似性は事前学習で学習済みなので、文に使用されている単語・品詞の類似性でもって似ている似ていないを考える段階ではないということだ。
あきらかに類似していない文のペア
文1:生態学や行動学、認知科学といった多様な学問から、人間やチンパンジーなどの霊長類を総合的に研究した。
文2:炊き込みご飯は手間がかかるのがちょっと難点ですが、実は電子レンジを使えばあっという間にできちゃいます。
この2つの文はほぼすべてのトークンに類似性が見られないので、事前学習モデルのみでも類似していないことは計算できる。ここまで異なる意味の要素が使われているとしっかり事前学習したモデルでは出力されるそれぞれのトークンの特徴量は大きく異なる値になるからだ。
つまり「あきらかに類似していない文のペア」のようなペアはどうでもよくて、以下ようなの意地悪な文のペアを適切に評価できなければいけないということだ。
文1:向上心を持つことで職業的専門性を高められる。
文2:職業的専門性を高めることで向上心を持つことができる。
文の自然さはさておき、2つの文は、手段と結果の順序が異なるので人間的な読解力でいうと"似ていない"と判断するべきである。これを意味的に近いと判断する人は、中学生レベルの国語ができないことになる。このように使用されているワードの多くが同じまたは、意味的に近いものばかりでも、コンピュータは"文の並び"から適切に意味を読解できなければいけないのである。
我々人間はこの例のように短い文であれば、簡単に意味の類似性を判断できるがもう少し長くなると一気に難しくなる。したがって、このレベルのクオリティでデータセットを膨大に用意するのは非常に大変だということがわかる。そして当然機械的にそれらを用意することなど不可能に思える。
要するにBert-STSのファインチューニングでは、乱暴な言い方をすると、文法(単語のシーケンス)による意味の影響を学習することを意味する。少なくとも今回大量の試行ではそのように思える結果が多く出ているので、私はそのように理解している。ともあれ、前回事前学習で作成したElectraモデルに膨大なデータセットでもってファインチューニングしてみた。結果は次回。